The CyberSEO Pro plugin includes a powerful capability that allows you to extract full-text articles from HTML pages using the container tag. This functionality can help you display complete articles on your site rather than just snippets or summaries, ensuring your site’s content is unique and informative.
In previous versions of CyberSEO Pro, you could use the universal Full-Text RSS script to extract full-text articles from arbitrary webpages. While Full-Text RSS script is very powerful and can extract almost any article, it’s not almighty and sometimes fails or is unable to correctly extract certain parts of HTML code, such as embedded videos, etc.
This method is still available as before, but there is a new one that enables you to extract a full-text article from any webpage with a fixed HTML layout, even if the Full-Text RSS script struggles with it. Just note that this new method must be tailored for each particular website, according to its internal HTML layout. As a result, it won’t work with sources like Google News RSS feeds, which are linked to different websites with their own unique HTML layouts.
Below is a guide through the process of using the container tag method using browser inspector tools such as Firefox or Chrome. Understanding that not everyone is familiar with HTML or web development, this guide has been designed to be as simple and easy to follow as possible.
Step 1: Find the container tag
- Open the webpage containing the article you want to extract in either Firefox or Chrome.
- Right-click on the main content area of the article and select “Inspect” (Firefox) or “Inspect Element” (Chrome) from the context menu, or press <F12>. This will open the browser’s Inspector tool, displaying the HTML structure of the page.
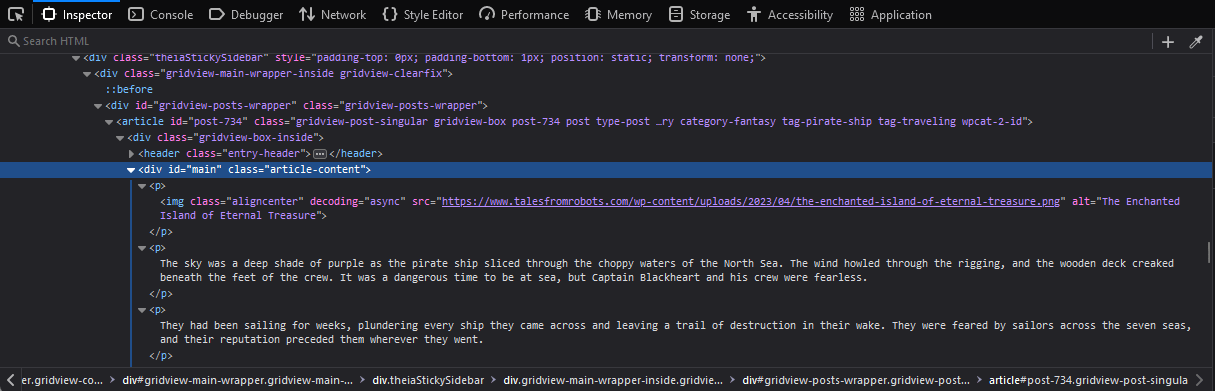
- In the Inspector tool, you’ll see the HTML element that wraps around the main content of the article highlighted. This is the container tag. It could be a
<div>,<section>,<article>, or another similar HTML element.
Step 2: Identify the attributes
- Examine the highlighted container tag in the Inspector tool to find its attributes. Attributes are properties of an HTML element that provide additional information about it. Common attributes include
class,id,style, etc. - Make a note of the attribute(s) and their corresponding values. For example, if the container tag is
<div id="main" class="article-content">, the attributes areclasswith the value"article-content"andidwith the value"main".
Step 3: Configure the CyberSEO Pro plugin
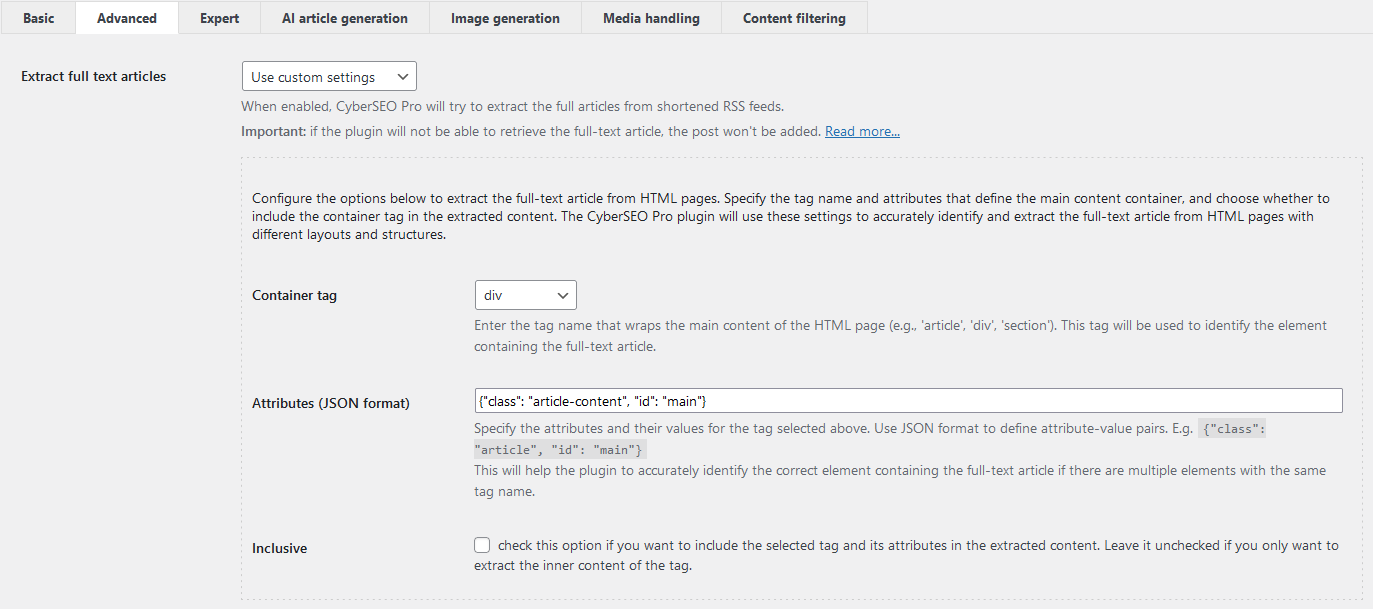
- In your feed settings, navigate to the “Advanced” tab.
- Select “Use custom settings” in the Extract full text articles drop-down menu.
- In the “Container tag” field, enter the tag name you found in Step 1 (e.g.,
div,article,section). For the example above it’sdiv. - In the “Attributes (JSON format)” field, enter the attributes and their values in JSON format, as found in Step 2. For our example, you would enter
{"class": "article-content", "id": "main"}. - Choose whether to include the container tag and its attributes in the extracted content by checking or unchecking the “Inclusive” option.
- Save your changes and pull the feed to test the extraction.
By following these steps, you can easily configure the CyberSEO Pro plugin to extract full text articles from HTML pages using the container tag feature. With a little practice, you’ll be able to identify container tags and their attributes with ease, ensuring your site has the most comprehensive and unique content possible. While this approach may not work for aggregator feeds like Google News or NewsAPI, it is an effective solution for extracting full-text articles from individual websites with consistent HTML layouts.
The described above method uses XPath to process the original HTML page. Unfortunately, not all webpages are formatted correctly, and their HTML code may contain errors. In this case, full-text article extraction using container tags may not work as well.
So the only way to extract the article will involve some simple PHP coding. In order to implement it, click on the “Expert” tab in your feed settings, find the “Custom PHP code” box and put there your PHP code that extracts the article from an HTML source. A link to the importing HTML document is contained in the $post['link'] variable, while the extracted article must be stored in $post['post_content']. So if the desired article is located between some unique blocks of HTML code, you can easily extract it using the preg_match function.
For example, let’s say you want to extract the part of the original HTML document that contains “The Article” like this:
<div class="entry-content"> The Article </div><!-- .entry-content -->
Then your custom PHP code should look like the following:
$content = cseo_file_get_contents($post['link']);
if (preg_match('/<div class="entry-content">(.*?)<\/div><!-- \.entry-content -->/s', $content, $matches)) {
$post['post_content'] = $matches[1];
} else {
$post = false;
}
The code above uses the cseo_file_get_contents function to load the importing HTML document into the $content variable when preg_match searches for a given text pattern. If the article is found, it’s stored in the $post['post_content'] variable. Otherwise, the post is skipped and no article is generated ($post = false;).
By following the steps outlined in this guide, you can ensure that you import high-quality, full-text content to your WordPress site using the CyberSEO Pro plugin.